
The Exponential Compute Ramp
How Useable FLOPs Are Powering AI
Over the last fifteen years I, like many, have been consistently amazed by AI's progress. Its core driver is, however, surprisingly simple.
The number of useable floating-point operations (FLOPs) - the actual computational work we can extract from our hardware - is increasing exponentially. When you look back, the numbers are truly eye-watering. Since we founded DeepMind in 2010, training compute for frontier AI models has grown by 1 trillion-fold, from 10^14 FLOPs for early deep learning models to over 10^26 FLOPs for the largest models of 2025. This is an explosion of computation. I remember realizing a single training run would cost more than all our previous experiments combined. But authorizing it anyway, because we could feel what was coming.
Everything else in AI follows this core fact, this epic generational compute ramp. This is significant because it means that if this trend continues, so does progress in AI. Talk of a new generation of ultra-capable models and agents relies on this explosion continuing.
It will.
This exponential is driven by a constellation of hardware and software advances working in concert under the hood. At Microsoft, we're now pushing this frontier ourselves with custom silicon. Our Maia 200 chip for example, built on TSMC's 3 nanometer process with 140 billion transistors, delivers over 10 petaFLOPS (10^15 FLOPs/second). When you start to grapple with these underlying drivers, it becomes easier to see how progress in AI will continue at a breakneck pace. This is why I'm optimistic we will keep delivering huge leaps in what AI can do.
Too often AI skeptics point to a slowing down of Moore's Law, or a lack of data or limitation on energy, but when you look at the combined forces driving the underlying exponential trend, the AI capabilities it produces seem quite easy to predict.
And yet too often the full consequences of this progress get overlooked. This single fact - the ongoing reality of scaling - has immense implications, for what it means to be human and how we organize society. AI is the most important transformation in history. Full stop. The interlinked set of innovations currently unfolding means none of it is speculative. It's critical therefore that everyone finds a way to get a deep intuition for its inevitability. That's the purpose of this essay: I want to bring to life a complex and fast-moving reality hard to appreciate outside the confines of a data center.
And there's no better way to grasp it than through a simple thought experiment.
The Office of Calculators
Here's a simple way of thinking about AI training clusters.
Rather than giant data centers, picture a room full of people sitting at desks working away on calculators. Each worker is fed a set of numbers to punch into the calculator. When they hit the equals button, that's one FLOP, or one unit of work the AI training job can do.
If you want more calculation, you can of course add more "people". For years, this is exactly what we've done. We've been adding more parallel processing to our chips, or people to that room. But there are bottlenecks. Sometimes the number crunchers sit idle waiting to be told which numbers to type. Useable FLOPs have been constrained not just by the number of calculators, but by how they're used, by how quickly they can get their numbers to crunch; in other words, by memory and data transfer.
The workers are fast, sure, but they spend a lot of their time drumming their fingers on the desk, waiting for their next assignment to come down the pipe. So it's not just about the number of calculators you have then; it's about ensuring they never have to pause.
What's happening now is a revolution in coordination. Hardware improvements beyond the chip itself, combined with software breakthroughs, are narrowing this gap dramatically. The time waiting for numbers to calculate is shrinking. Cutting edge data centers are now the size of multiple football pitches. Each number cruncher is wired together with thousands of others using fiber optic cables able to send and receive up to 800 Gb/s. That's 800 billion bits of information per second between each person sitting at a calculator (a figure soon to rise to 1.6 terabits). Entire campuses of chips are networked together to communicate almost instantaneously and "think" as one. This allows them to calculate faster, share data instantly, and, critically, work in unison on data too big for any one chip.
Here's how the analogy plays out. Think of one person hitting enter on a calculator as the most basic unit. As chips got better and we scaled up, we moved to many, many people in one room, all working faster. Now we have multiple buildings full of those rooms of people calculating, all working in unison, all faster than ever. Think of it as the difference between a single person with a calculator working slowly and a city or planet of calculators working at speed.
The story of AI's compute explosion unfolds in several acts. It's one of better chips. Then, of larger compute "nodes" (a node is essentially a single unit of compute like a server which are then organized into racks and clusters of racks that function as one system). Then better communication within each node, then between nodes in the rack, and then across racks in the cluster to create one big supercomputer.
Each act represents a transformation in how we extract useable work from our hardware. Together, they drive a new exponential, one that is compounding fast, scaling to extraordinary new heights, and powering the future of AI and everything that comes with it.
This exponential - useable FLOPs and the phase transitions in AI capability driven by it - is the technological story of our time.
Act One: The Workers Get Faster

The first revolution is the shift to GPUs and their relentless improvement.
The GPU, or Graphics Processing Unit, was originally designed to render video games. It turned out to be one of history's happiest accidents. By pure luck, the architecture for playing Quake was mathematically isomorphic to the operations required for training neural networks: massively parallel matrix multiplication. Where a traditional CPU (the Central Processing Unit) excels at performing one complex calculation very quickly, a GPU can perform thousands of simpler calculations in parallel. For deep learning models, which churn through astronomical quantities of basic mathematical operations, this was transformative.
The pivot from CPUs to GPUs broke AI away from traditional computing entirely. And once the industry committed to GPUs, the improvements came thick and fast, driven by specialized circuits called Tensor Cores, engineered specifically to chew through the linear algebra that underpins everything from Copilot to MatterGen, our generative model for materials science.
To return to our metaphor: the transition to GPUs and their continued improvements mean the individual calculator operators got dramatically faster. What started as a child laboriously doing long multiplication by hand became an adult with a pencil, then an adult with a calculator, then an adult with a supercharged calculator designed for precisely this task.
The GPU numbers tell this story. In 2020, NVIDIA's Ampere A100 chip delivered 312 teraFLOPS of performance. By 2022, the Hopper H100 hit 989 teraFLOPS, more than three times faster. By 2024, the Blackwell B200 reached 2,250 teraFLOPS. That's a more than sevenfold increase in raw hardware capability in just four years. Keep in mind that 1 teraFLOP is already a trillion calculations per second!
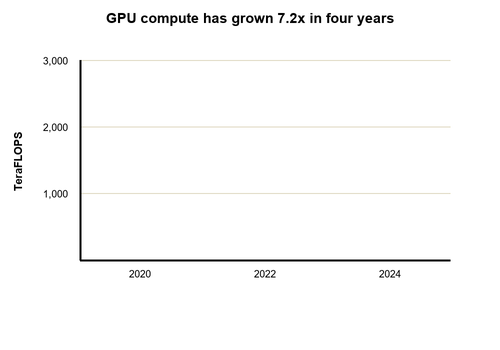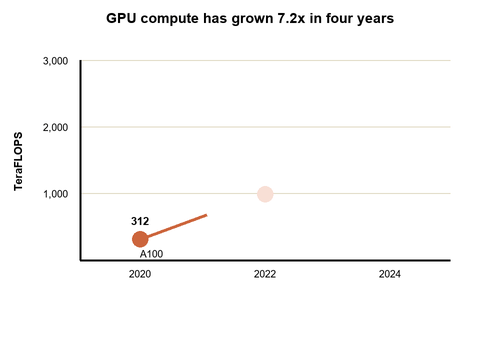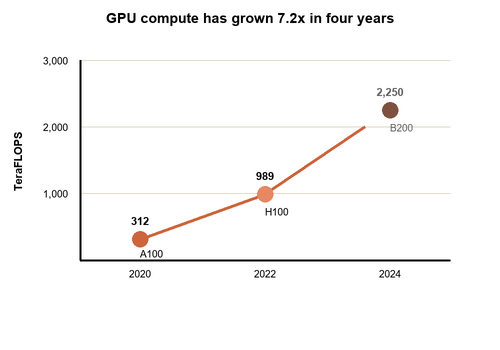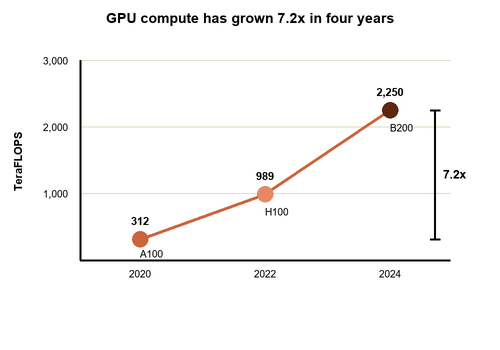 GPU TeraFLOPS growth, 2020-2024
GPU TeraFLOPS growth, 2020-2024
And engineering keeps pushing further. The Blackwell B200 stitches together two massive silicon dies over a 10 terabyte-per-second link, creating a unified mathematical monster with 208 billion transistors. NVIDIA's Vera Rubin architecture arrives this year, promising yet another generational leap. We've moved from monolithic chips to "chiplets," slabs of silicon functioning as a single logical unit, packing more computation into less space than anyone thought possible a decade ago.
To get a sense of what this scale of computation means, imagine that every person on Earth uses a calculator to perform one calculation per second. Everyone works 24 hours a day without rest. Every second, we all hit equals on the calculator for a long digit multiplication. It would take all of us together hitting equals non-stop about 22 days to complete what a single GB300 chip does in just one second. That's a mind-blowing level of computation.
At Microsoft, we're also pushing these frontiers. Our new Maia 200 inference chip is the most performant first-party silicon of any hyperscaler. Delivering 30% better performance per dollar than the latest other hardware in our fleet, it can run today's largest models with headroom to spare for even bigger ones.
 The Maia 200 chip
The Maia 200 chip
But faster workers alone don't solve the problem. Because even the fastest calculator operator is useless if they're idle, sitting around waiting for someone to hand them the numbers to crunch.
Act Two: The Numbers Arrive Faster

GPUs need to access data from memory and storage to know what calculations to perform. Peak theoretical FLOPs have always been limited by this data transfer bottleneck, meaning effective compute (the actual number of calculations your computer can run during an AI training job) hasn't grown at quite the same rate as the headline numbers suggested. This is the "Memory Wall," and cracking it has been one of the great engineering achievements of the past few years.
One solution is High Bandwidth Memory (HBM). Rather than spreading memory chips across a circuit board, HBM stacks them vertically like tiny skyscrapers, placing them right next to the processor on the same piece of silicon. Thousands of microscopic elevators called Through-Silicon Vias connect memory to logic. Without this proximity, GPUs would spend most of their time waiting for data. HBM keeps the numbers flowing.
The progress generation over generation has again been remarkable. In 2017 a top end V100 shipped with 32GB of HBM2. The A100 more than doubled that to 80GB of HBM2e, and with each generation bandwidth increased alongside capacity. In 2020, the A100 delivered 2 TB/s. Then came HBM3, a newer, faster generation of memory that effectively triples the bandwidth and significantly increases capacity. By 2022, the H100 pushed to 80GB of HBM3 with 3.35 TB/s of bandwidth, and by 2024, the GB200 reached 192GB of HBM3e per GPU with 8 TB/s of bandwidth. So while the raw processing power on each chip grew by roughly 8x in recent years, memory bandwidth grew by about 4x. That's not quite exponential, but it's enough to keep the bottleneck from strangling progress. Demand for memory is now so high thanks to AI it's caused a global crunch in supply hitting the cost of new smartphones with up to 200% increases.
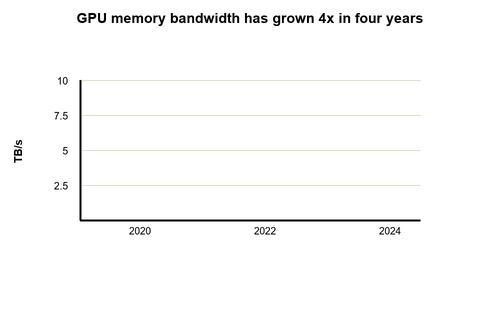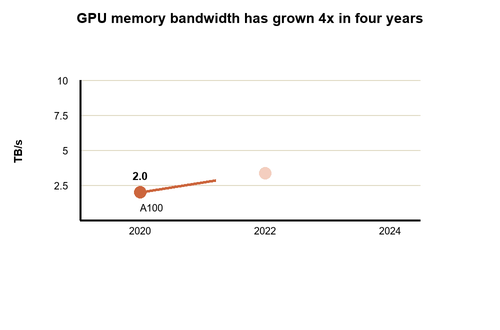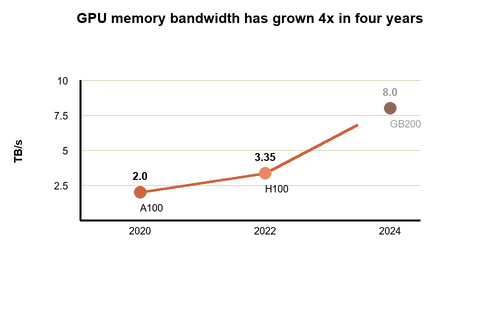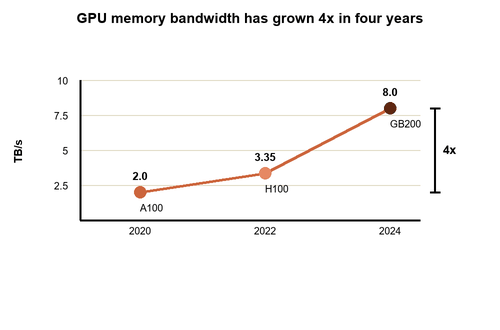 GPU memory bandwidth growth
GPU memory bandwidth growth
The GB200 also pushed another new innovation: the CPU and GPU sitting together, sharing a unified memory pool. Data that once had to be loaded by the CPU, processed, and then transferred to the GPU can now flow more seamlessly. The CPU writes to memory, and the GPU reads from the same place. One less bottleneck. One less pause. It's as though each office worker now has an aide sitting at the same desk able to help organize all the numbers being input into the calculator.
There's another breakthrough here, equally important but less well understood: we've learned to work with lower precision. When numbers are fed into the calculator they are represented in binary form and since they are so large, they're compressed into a fixed representation. For years, models were trained using 32-bit floating-point numbers, assuming we needed that level of granular detail to capture intelligence. It turns out we don't. We can reduce precision to just 8-bits or even 4-bit numbers without losing too much model accuracy. In our metaphor, the workers no longer have to type in 32 decimals of precision. Instead, 4 decimals will do. This allows them to finish each calculation much faster while still getting good results.
The combination of faster memory and lower precision means our calculator operators are finally getting their data fast enough to stay busy. But there's yet another revolution. It transforms the scale of what's possible.
We're going big.
Act Three: The Office Becomes a Campus

We've moved from one giant room of people working together to 72 giant rooms of people working together: that is, 72 GPUs in a single rack, all hitting enter on their calculators in perfect synchronization, working as a single humungous calculating machine.
Today, these racks are being fully connected, enabling us to stitch together hundreds of thousands of chips into warehouse-sized supercomputers spanning dozens of football pitches. A modern data center is a near town-sized site. It means we go from a single office to multiple buildings, all full of rooms full of workers, all collaborating on the same calculation.
This is where the coordination challenge becomes acute. Why have a million calculator operators if they can't communicate? The breakthrough here comes from interconnect technologies that allow chips to share memory and data as if they were a single giant brain.
Take the NVL72 system. It connects 72 GPUs using specialized NVLink technology, allowing them to send information with aggregate bandwidth of around 130 terabytes per second. That is a truly eye watering amount of information exchange. It's one quadrillion bits of information per second for each 72 GPU system... all working in perfect synchronization and for complex inference tasks, effectively up to 30x faster. And soon we'll be at 144 GPUs per rack.
Beyond the rack, we're connecting entire data centers and even linking data centers together. InfiniBand network speeds have progressed from 200 gigabits per second (HDR, 2018) to 400 gigabits per second (NDR, 2022) to 800 gigabits per second (XDR, 2025), with 1.6 terabits per second arriving this year. That's the equivalent of transferring 50 high-definition movies every second. Ultra Ethernet will push speeds even higher, approaching the theoretical limits of light itself.
 Server racks for the GB200
Server racks for the GB200
What InfiniBand and these high-speed networks do is allow entire data centers to operate as a single coherent compute cluster. Rather than training a model on isolated racks, we can now distribute workloads across hundreds of thousands of GPUs simultaneously, regardless of which physical rack or even which building they sit in. The network is fast enough that the GPUs can synchronize their calculations as though they were all on the same chip. This is how we've gone from thousand-GPU clusters to hundred-thousand-GPU clusters - and soon million-GPU clusters and beyond.
In 2012, AlexNet - the image recognition model that sparked the deep learning revolution - trained on just 2 GPUs. By 2015, state-of-the-art models like Inception-V3 used 50 GPUs. The largest system submitted to MLPerf in 2020 used around 2,000 GPUs. In 2023, at Inflection, our cluster of 3,500 GPUs set a new record on MLPerf. By 2024, NVIDIA's Eos cluster submitted benchmarks running on over 11,000 H100s - a nearly 6x increase in cluster size in just four years, with each of those GPUs individually far, far more powerful than their predecessors.
From 2 to 11,000 (much better) GPUs in just over a decade... That's what drives AI. And it's worth saying that frontier labs have always had access to more than what they submitted to MLPerf. Clusters of 100,000s of GPUs and upward are now normal.
 A Microsoft data center in Arizona
A Microsoft data center in Arizona
Let's return to our metaphor one last time.
We've installed telephone lines between buildings, then early fiber-optic cables, then something that feels almost telepathic in its speed and bandwidth. An entire campus or city can now work in unison, not just a single room. The calculations that once required a single worker now harness millions, coordinated with such precision that they function as a single cognitive entity.
The Collision of Exponentials
Here is what I think makes this moment so significant: all of the trends combine and reinforce each other. When you combine an eightfold increase in chip performance with a step-function change in memory bandwidth, with a revolution in interconnect speeds, and on top of unprecedented levels of investment to build it all, the result is not simply more compute.
It is an explosion of compute that's been compounding for over a decade and isn't stopping now. It's a many-faceted story but with a single driving plot - more compute - and a crystal-clear ending - better AI. Thanks to this process, I've watched researchers spend weeks tuning a model, only to have the next generation of hardware render those optimizations almost irrelevant overnight.
The training benchmarks tell the story concretely, showing how we can deploy so much more compute than even in the recent past thanks to these gains.
In 2020, training a neural network (BERT) on 8 V100 GPUs took 167 minutes. By 2023, the same benchmark on 8 H100s completed in just 5.5 minutes - a 30x speedup. But then scaling pushed it further still, and 256 H100s did it in under 20 seconds - a further 16.5x speedup even when communication overhead dominates. To put this in perspective: Moore's Law - the famous observation that transistor density doubles roughly every two years - would predict only about a 3x improvement over this three-year period. We saw 30x and 16.5x. What's different here is that we're adding more chips and innovating across many layers of the stack. The innovation and scaling are broader based than just Moore's Law.
Today's leading systems push further still, with early benchmarks showing 8 GB200s completing BERT training in 3.4 minutes, nearly 50 times faster than 8 V100s from just five years prior. Maia 200 embodies this collision. Custom silicon, purpose-built memory architecture, and a novel two-tier scale-up network that connects 6,144 accelerators... all engineered as one unified system with incredibly powerful results. And remember this goes way beyond faster chips. It's about faster memory, faster interconnects and better software, all compounding together.
Incredibly, this isn't even the end of the story. Algorithmic innovations are improving performance at roughly twice the rate of hardware gains alone. Research suggests that the compute required to reach a fixed level of performance halves approximately every 8 months - faster even than the traditional 18-24 month doubling time of Moore's Law. The inference costs of some recent models answering PhD-level science questions have collapsed by up to 900x on an annualized basis. Intelligence is hence becoming radically cheaper to deploy. When you couple this with the kind of efficiencies available from Maia, it's clear the cost of cognitive work is approaching zero.
When you hear about scaling, this is the reality behind it.
What Comes Next
The human brain is a masterpiece of biology, but it's calibrated for a world we're leaving behind. When our ancestors tracked gazelles across the savannah, survival depended on understanding linearity. Walk for an hour, cover a certain distance. Walk for two, cover double. When we gathered berries, we did so sequentially - one, then another, then another. Our intuition is safe in the arithmetic progression of 1, 2, 3...
And yet AI is not linear. It is exponential. This exponential has held for many years. Our intuitions catastrophically fail when facing an exponential reality like this.
Skeptics argue we're hitting a wall. They say that the paradigm is played out, the scaling laws will fail, that the curve must flatten. I take the opposite view and see no reason to believe the scaling laws are anywhere like finished.
But the industrial machinery now being assembled, all of this innovation that ladders up to the $100 billion clusters, the 10 gigawatt power draws, the warehouse-scale supercomputers, this is the apparatus that will settle the debate. These are not abstract concepts or science fiction. They are today's steel and silicon realities, breaking ground right now.
By the end of 2028, we are looking at another 1000x increase in effective compute.
Another three orders of magnitude. The next phase of the scaling era. By 2030, it's plausible that we'll be bringing an additional 200 GW of compute online every year - akin to the peak energy use of the UK, France, Germany and Italy put together. I believe it drives the transition from chatbots to near human-level agents - semi-autonomous systems capable of writing code for days, weeks and months long projects, making calls, negotiating contracts, managing logistics. Forget basic assistants that answer questions and think teams of AI workers that deliberate, collaborate and execute. It is this generation of AI that will unlock seismic gains in productivity and lead to genuine new breakthroughs.
There is, of course, a constraint: energy. Right now, a single refrigerator-sized AI rack like the NVL72 consumes 120 kilowatts or the equivalent of roughly 100 homes. But this immense hunger for power is colliding with another exponential: the collapsing cost of renewable energy. Solar costs have fallen nearly 100x over the last fifty years. Battery prices have dropped by 97% over three decades. Meanwhile we're also seeing the emergence of more energy efficient accelerators and model architectures. The pathway to sustainable expansion is not yet realized but is at least becoming clear.
The capital is deployed. The engineering is delivering. Our calculator operators are faster, their instructions arrive quicker, and they number in the millions... all working in concert on problems that would have taken civilizations to solve.
This is the epic compute ramp of our time, the exponential driving AI. And it is only just beginning.
What remains is for us to grasp what it means. We are facing cognitive abundance. As AI progress continues unabated, it's worth pausing to absorb the enormity of what we're building. Our linear intuitions will fail us here.
Welcome to the age of exponential AI.
Recent Articles


.jpg&w=3840&q=75)

Towards Humanist Superintelligence
What kind of AI does the world really want? At Microsoft AI, we're working towards Humanist Superintelligence: incredibly advanced AI capabilities that always work for, in service of, people and humanity.